Part1
要理解 HTTP/2 为何在 Web 性能领域中引起轰动,首先要了解有什么问题需要解决和为什么需要它。因此,本书的第一部分就向那些不熟悉 HTTP/1 的读者介绍 HTTP/1;然后阐述为什么需要 HTTP/2。从一个较高的层面讨论 HTTP/2 如何工作,低层面的细节留在本书的后面部分再讨论。相反,通过讨论如何将 HTTP/2 部署到你的站点来结束本部分。
本章向你介绍当今 Web 工作原理,并解释本书其余部分的一些关键概念;然后介绍 HTTP 和其版本历史。我希望本书的读者至少对第一章的内容有所了解,当然也不要忽略它,利用本章来复习你的基础。
1.1 How the web works
略
1.1.1 The internet versus the World Wide Web
对很多人来说,internet 和万维网是同义的,但是两者之间是有巨大差异的
internet 是通过 IP 互联的公共计算机集合,通过 IP 传递来共享消息。提供了很多服务,包括万维网,email,文件分享和网络电话。万维网(或者叫 web)作为 internet 的一部分,是其中最可视化的一部分。并且人们通常通过 web-email 的终端(比如 Gmail,Hotmail 和 Yahoo)来查看 email,有些也用 web 与 internet 进行交互
HTTP 是 web 浏览器请求 web 页面的方式。这是 Tim Berners-Lee 发明 web 时定义的三种技术之一,另外两种是资源的唯一标识符(Uniform Resource Locators, 或者称为 URLs)和超文本标记语言(Htypertext Markup Language, HTML)。internet 的其他组成部分有自己的协议和标准来定义工作如何工作以及如何传递消息(比如 email 与 SMTP,IMAP 和 POP)。在提到 HTTP 时,你主要与万维网交互,但是这条线越来越模糊,因为越来越多的服务构建在 HTTP 之上,不止于传统的 web 终端(译者注:一般是浏览器),这意味着 web 本身的定义越来越困惑。这些服务(比如 REST 或者 SOAP)可以被 web 页面使用,也可以不是 web 页面(比如手机的 app 可以复用)。物联网中表示与其他设备进行交互的设备(计算机,手机 app 或者其他物联网设备),经常通过 HTTP 通信完成。结果就是,你可以使用 HTTP 通过手机 app 发送灯的开关指令。
尽管 internet 由无数的服务组成,但是随着 web 持续的增长,其他的服务使用者正越来越少。互联网早期中诸如 BBS 和 IRC 今天已经几乎消失了,取而代之的是 web 论坛,社交媒体网站和聊天应用。
所有这一切意味着,尽管术语 World Wide Web 和* the internet *不能直接画等号,随着 web--至少 HTTP 使用的增长,两个术语的含义差距可能越来越小。
1.1.2 what happens when you browse the web?
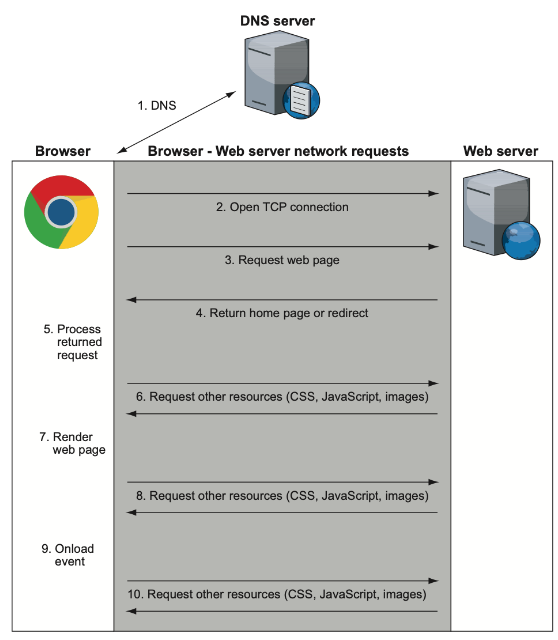
如上图,假设你启动了一个浏览器,然后访问 www.google.com ,几秒内发生了如下事情:
- 浏览器从 DNS(Domain Name System) 服务器获取域名 www.google.com 的真实 IP 地址 如果你将 IP 地址看做电话号码,DNS 就是电话簿。IP 地址或者是老的 IPv4 地址(比如 216.58.192.4,还比较对人友好)或者是新的 IPv6 地址(比如 2607:f8b0:4005:801:0:0:0:2004,则完全转向了机器友好)。IPv6 地址就是为了应对激增的“电话号码”。 请注意,由于 Internet 的全球性,大公司通常在全球范围内有多个服务器。当你向 DNS 服务器请求 IP 地址时,通常会返回给你最近的服务器地址,使响应更快。例如,美国和欧洲会获取 www.google.com 的不同 IP 地址。
- 浏览器会通过获取到的 IP 地址与标准端口(80 或者 443)与服务器开启一个 TCP 连接 [略过关于 TCP/IP 的解释] 一个服务器可以提供多个服务(email, FTP, HTTP/HTTPS web server),不同的端口允许将不同的服务集中在一个 IP 地址下,就像企业可能为每个员工提供电话分机。
- 浏览器与 web 服务器建立连接之后,就可以开始请求站点。这里就是 HTTP 的工作原理了,将在下一节讨论,这里只需要通过 HTTP 协议向 Google 服务器请求 Google home 页面。如果使用 HTTPS,还有个额外建立加密 TCP 连接的部分
- Google 服务器响应浏览器 URL 的请求。[略]
- 浏览器处理返回来的响应。假定返回的是 HTML,浏览器开始解析 HTML 代码然后在内存中建立 DOM(Document Object Model),页面的内部表示方式。整个处理过程中,浏览器加载页面显示需要的其他资源,例如 CSS, JavaScript 和图片。
- 浏览器会请求所需要的资源。Google 保持了主页面的简介,只需要 16 个其他资源就可以完成加载。每个资源的请求都是通过类似的方式,从步骤 1 到步骤 6,是的,包含本步骤,因为这些资源可能会反过来请求其他资源。一般的网站不像 Google 那么简洁,通常来自许多域名,所以必须不断重复步骤 1-6。这是导致浏览器缓慢的主要愿意之一,这也是推动 HTTP/2 的原因,主要目的就是使得这些额外请求更快,这将在以后的章节讨论
- 当浏览器有了足够的资源,就开始在屏幕上呈现页面。选择何时开始呈现是一个困难的任务。如果浏览器等所有资源下载到本地之后再呈现,就会很慢。但是如果渲染开始过早,就会导致页面一直刷新,如果你已经在阅读页面,这很烦人。对构成 web 页面的技术-- HTML/CSS/JavaScript 熟悉可以优化页面好用,但是很多网站没有优化
- 在页面初始化完之后,浏览器继续在后台下载需要的资源,然后刷新加载,所以你可以看到没有图的页面,然后图再加载出来
- 当页面完全加载完成,浏览器停止加载图标(大多数浏览器在地址栏上旋转的图标),并触发 OnLoad JavaScript 事件,这是 JavaScript 代码里获得页面已经加载完成的标志
- 此时,页面加载完成,但是浏览器并没有停止发送请求。网页是静态信息的时代已经过去,现在许多网页都是功能丰富的应用,会与 Internet 中的各种服务器通信,此内容可能是用户操作,比如在 Google 主页,输入搜索内容之后可以看到搜索建议而不必点击搜索按钮,或者应用驱动的动作,比如你的 Facebook 或者 Twitter 自动刷新而不必操作。这些动作通常发生在后台,是透明的,尤其是跟踪你在网站上的操作向网站所有者或者广告商发送分析报告。
正如描述的,当输入 URL 时发生了很多事情,几乎就在扎眼的瞬间这些事情就完成了。每个步骤都能展开一本书来讨论,本书着重并深入讨论步骤 3-8(通过 HTTP 加载站点)。稍后的某些章节(尤其是第 9 章)涉及了步骤 2(HTTP 使用的底层网络连接)。
1.2 What is HTTP?
上一节特意介绍了 HTTP 工作的详细流程,因此你可以理解 HTTP 如何适应更广泛的* internet*。本节,我简洁描述一下 HTTP 的工作原理和使用方法。
正如之前提到过的,HTTP 代表* Hypertext Transfer Protocol*。顾名思义,HTTP 最初旨在传输超文本文档(包括指向其他文档的链接的文档),第一个版本只支持文档。很快,开发人员意识到这个协议可以用于传输其他类型的文件(比如图片),所以 HTTP 的超文本部分不太具有意义,但是考虑到 HTTP 的广泛使用,现在对齐重命名已经为时已晚。
HTTP 依赖于网络连接,通过由 TCP/IP 提供,建立一个物理层面的连接(Ethernet,Wi-Fi 等)。因为通信协议是分层的,每层做好自己的事。HTTP 不关心底层网络连接的建立过程。尽管 HTTP 应用应注意如何处理网络故障或者断开连接,但是协议本身不考虑这些问题。
OSI(Open Systems Interconnection)模型是一个概念模型,这个模型包含七层,尽管这个模型不能准确的对应真实网络中的情况,仍然经常用于描述网络的分层概念。TCP 至少跨越了这个模型中的两层,也可能是三层,具体取决于怎么定义这些层。图 1.2 大致显示了该模型如何映射到 Web 流量和 HTTP 对应该模型的位置。
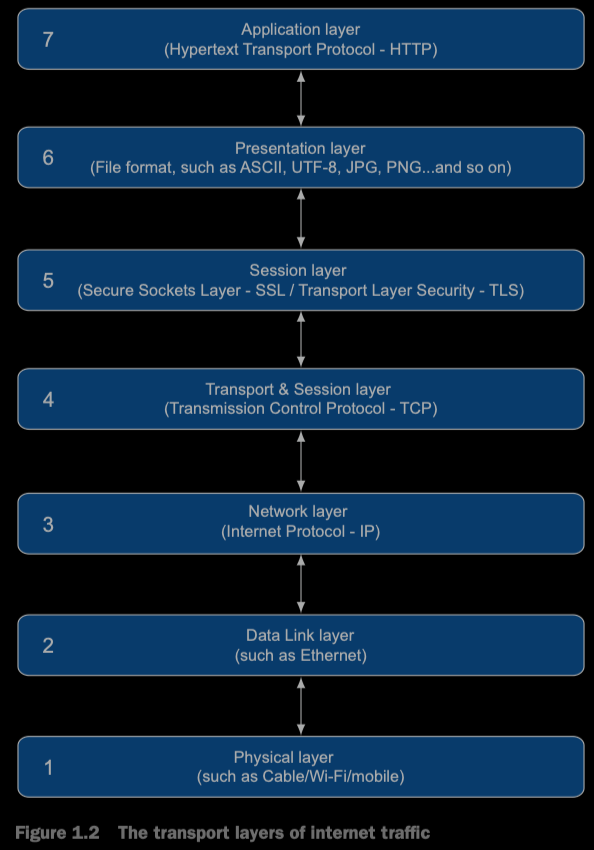
关于每层的确切定义确实存在一定争议。在 internet 这种复杂的系统中,并非所有内容都可以像开发者想象的那样严格进行分类分离。事实上,Internet 工程组(IETF)警示了不要过于关注分层。但是这可以从较高的层次上帮助理解 HTTP 位于模型中的什么位置以及如何依赖底层进行工作。Many web applications are built on top of HTTP, so the Application layer, for example, refers more to networking layers than to JavaScript applications(译者注:本句不太会翻译:),直接放到这吧)
HTTP 是一个请求-响应协议。web 浏览器使用 HTTP 语法向服务器发出一个请求,响应的消息里附带了请求的资源。HTTP 成功的关键是简单。正如你将在后面章节看到的,简单性也是 HTTP/2 的目标,不过为了效率牺牲了一些简单性。
HTTP 请求的基本语法如下
GET /page.html\n\r
结尾处是 newline 的表示。这就是 HTTP 最简单的表示,如此简单。表示你要 GET 资源/page.html。要记住的是,此时你已经使用比如 TCP/IP 连接了正确的服务器,所以你只需要简单向服务请求你想要的资源,而不用关注连接以及连接的管理。
HTTP 的第一个版本(0.9)只有 GET 方法,这里你会疑惑为什么需要传递 GET,因为在后面的版本中引入了更多的方法,因此对 HTTP 发明者预见了会有更多的方法表示敬意。下一节,将讨论 HTTP 的各个版本,不过语法还是这里 GET 这种格式。
考虑一个实际中的例子,以下原文举例了使用 Telnet/NC/windows 网络连接工具连接 www.google.com,然后手动输入 HTTP 命令获取响应,此处略去不翻译。
1.3 The syntax and history of HTTP
HTTP 由 Tim Berners-Lee 和他的 CERN 研究团队在 1989 年提出。旨在成为一种实现互联计算机网络的方式,以提供对研究资料的访问并连接它们,以便它们可以轻松地实时互相引用,单击连接可以打开关联的文档。这种系统的 idea 已经存在很长时间,超文本这个词 1960 年代就被创造出来。随着互联网在 1980 年代的增长,可能可以实现这个 idea 了,在 1989 年和 1990 年,Berners-Lee 提出了构建这样一个系统的建议,他构建了基于 HTTP 的第一个 web 服务,和第一个请求 HTML 并显示的 web 浏览器。
1.3.1 HTTP/0.9
第一个 HTTP 发布的规范是 0.9 版本,发布于 1991 年。规范文件少于 700 个单次。它指定通过 TCP/IP(或者类似面向连接的服务)与服务器和可选端口(如果未指定端口,则使用 80)建立连接。一行 ASCII 字符被发送,包含了GET和文档地址以及回车符和换行符(回车符可选)。服务端返回 HTML 格式的信息,定义为 ASCII 编码的字节流。它还指出,“消息通过服务器关闭连接而终止”,这就是为什么在先前的实例中每个请求之后关闭连接的原因。关于错误处理,规范指出“错误响应以 HTML 语法的可读文本形式给出,只能从内容上区分是正常响应还是错误响应”。它以以下文本结尾“请求是幂等的,服务端不需要在断开连接后保存任何请求的信息”。该规范给了我们 HTTP 的无状态部分,既是祝福(简单)也是祸根(因此必须使用 HTTP cookies 之类的技术来追踪状态,这对于复杂的应用是必需的)。
HTTP/0.9 中只会存在下面这种命令
GET /section/page.html \r\n
没有 HTTP 头部字段或者其他媒体诸如图片的概念。令人惊讶的是,这个简单的请求/响应协议(旨在提供研究资料的轻松访问)迅速催生了当今世界多媒体丰富的万维网。甚至从早期开始,Berners-Lee 就将他的发明命名为万维网,再次表明了他对于这个项目的远见并计划将其打造为全球化的系统。
1.3.2 HTTP/1.0
万维网几乎马上就成功了。根据 NetGraft 数据,到 1995 年 9 月,万维网就有了 19705 台主机。一个月之后,这个数字跃升至 31568,此后以惊人的速度增长。在撰写本文时,我们有了接近 2 亿个网站。到了 1995 年,HTTP/0.9 的简单协议的限制已经显而易见了,并且大多数 web 服务器已经实现了超出 0.9 规范的扩展。HTTP 工作组,由 Dave Raggett 牵头,开始修订一个更加通用的协议版本 HTTP/1.0。在 1996 年 5 月以 RFC1945 发布。IETF 发布 RFC(征求意见)文档,可以被接受为正式标准或者保留为非正式文档。HTTP/1.0 RFC 是一个非标准规范,在开头就描述自己为 memo(备忘),“本备忘为互联网社区提供信息,本备忘未指定任何形式的互联网标准”。
无论正式与否,HTTP/1.0 都添加了一些关键特性,包括
- 更多的方法:
HEAD和POST被加入 - 对所有消息一个可选的 HTTP 版本号,为了向后兼容,默认是 0.9 版本
- HTTP 头部,可以在请求和响应中提供资源的更多信息
- 一个三位数的响应代码,指示响应是否成功。此代码还使能了重定向请求,条件请求以及错误状态(404-Not Found 是最出名的一个)
这些急需的协议功能通过使用自然而然的发生了,HTTP/1.0 旨在记录现实中许多 web 服务器已经实现的功能,而不是定义新的选项。这些附加选项为 web 打开了很多新的机会,包括通过 HTTP header 声明 body 中的内容类型来在 web 页面中加入多媒体内容。
HTTP/1.0 METHODS
GET 方法与 HTTP/0.9 中的大致相同,尽管 header 的添加允许有条件的 GET(仅当自上次客户端获取的资源已更改时,才响应 GET 指令,否则回复资源未更改,客户端继续使用旧的即可)。而且,正如前面提到的,用户可以 GET 更多类型的资源,比如下载图片,视频和任何类型的多媒体资源。
HEAD 方法允许客户端在不下载资源的情况下获取资源的元信息(比如 HTTP header)。这个方法在很多情况非常有用。比如像 Google 这种网络爬虫,可以检查资源是否发生了变动,并且只在发生了改变的情况下才下载它,从而节省资源。
POST 方法更加有趣,允许客户端发送数据到服务端。用户可以使用 HTTP 来发布文件,而不必使用标准的文件传输方法将新的 HTML 文件直接放到服务器上,只要将 Web 服务器设置可以接收数据并处理即可。POST 不仅限于整个文件,可以用于更小的数据粒度。网站的表单通常使用 POST 方法,表单内容作为 field/value 对在 HTTP 请求的 body 中发送。因此 POST 方法允许将内容作为 HTTP 请求从客户端发向服务端,这表明 HTTP 请求也可以有 body,像 HTTP 的响应一样。
事实上,GET 可以通过 query 参数的方法传递给服务端,将参数以?的方式加载 URL 结尾。比如https://www.google.com/?q=search+string告诉了 Google 你正在搜索search+string。query 参数是最早的统一资源标识符(Uniform Resource Identifier, URI)规范,但是旨在提供可选参数阐明 URI,不是用作将数据上传到服务器。URL 也被限制了长度和内容(比如不能包含二进制内容),一些敏感的信息(比如密码,信用卡信息等)不应该保存在 URL 中,会导致很容易被查看。因此,POST 是发送数据的更好的选择,数据不可见(尽管通过 HTTP 发送的数据还是可以被看到,除非使用 HTTPs,这后面会提到)。另一个 GET 方法和 POST 方法的不同时,GET 是幂等的,POST 不是,意味着多个相同的 GET 方法获取的响应是一样的,而 POST 的结果不一定相同。例如刷新网站的标准页面,会显示相同的内容,如果刷新电子商务网站,浏览器可能会提示你是否重新提交数据,这可能导致你购买额外的商品(尽管电子商务网站应该保证这种事情不会发生)
HTTP REQUEST HEADERS
HTTP/0.9 中 GET 资源只有一行,HTTP/1.0 引入了 headers。header 允许请求提供额外的信息,可以使服务端用来决定如何处理请求。HTTP header 在原始请求行之后不同行提供,HTTP GET 请求可以变成这样:
GET /page.html HTTP/1.0
Header1: Value1
Header2: Value2
最后的换行符是必要的,表示请求 header 部分已经完成
HTTP headers 规范由 header name,一个冒号,header 内容组成,header name 不区分大小写。headers 可以跨越多行当你以 space 或者 tab 开始一个新行时,但是不建议这样做,很少有客户端或者服务器使用此格式,并且可能无法正确处理它们。可以发送多个相同类型的 header,它们在语义上与发送逗号分隔的版本是一样的,比如
GET /page.html HTTP/1.0
Header1: Value1
Header1: Value2
与
GET /page.html HTTP/1.0
Header1: Value1, Value2
意义是一样的。
尽管 HTTP/1.0 定义了一些标准 header,本示例还演示了 HTTP/1.0 允许自定义 header(比如上面的 Header1)而无需更新协议版本。协议被设计为可扩展的。但是规范明确指出“不能假定接收者认识这些字段”,并且可能被忽略,而标准的 header 应有符合 HTTP/1.1 服务器处理。
一个典型的 HTTP/1.0 GET 如下所示:
GET /page.html HTTP/1.0
Accept: text/html, application/xhtml+xml, image/jxr/, */*
Accept-Encoding: gzip, deflate, br
Accept-Language: en-GB, en-US,; q=0.8,en;q=0.6
Connection: keep-alive
Host: www.example.com
User-Agent: MyAwesomeWebBrowser 1.1
这个例子告诉服务器你可以接收的响应属于(HTML,XHTML,XML 等),你可以接收几种编码(比如 gzip,deflate 和 brotli,它们是用于压缩 HTTP 传输数据的方法),你更倾向于什么语言(GB English,然后是 US English,再然后是另一种格式的英语),以及你使用的浏览器和版本(MyAwesomeWebBrowser 1.1)。还告诉服务端保持连接打开(这个话题后面会提到)。整个请求由两个 return 字符结束。从这里开始,出于可读性原因,后面回省略 return 字符。你可以假定最后一行有两个 return 字符。
HTTP RESPONSE CODES
典型的 HTTP/1.0 响应如下:
HTTP/1.0 200 OK
Date: Sun, 25 Jun 2017 13:30:24 GMT
Content-Type: text/html
Server: Apache
<!doctype html>
<html>
<head>
...etc.
HTML 剩余部分随后提供。正如所示,响应的第一行是响应消息的 HTTP 版本,一个三位的 HTTP 状态码(200),文本的状态描述(OK)。状态码和文本描述是 HTTP/1.0 的新概念,HTTP/0.9 中没有状态码这种概念,错误只能在 HTML 本身中返回。下标表示了 HTTP/1.0 中定义的状态码
| Category | Value | Descritpion | Details |
|---|---|---|---|
| 1xx(informational) | N/A | N/A | HTTP/1.0 没有定义 1xx 的状态码,不过定义了这个种类 |
| 2xx(successfule) | 200 | OK | 这个代码是请求成功的标准响应码 |
| 201 | Created | 这个代码只会响应 POST 方法 | |
| 202 | Accepted | 这个请求被处理了但是尚未完成 | |
| 204 | No content | 请求已被接收并处理,但是响应 body 没有发送回去 | |
| 3xx(redirection) | 300 | Mutiple choices | 这个代码不直接被使用,3xx 类别意味着该资源存在与某一个(或者多个)位置,确切的响应提供了位置的更详细的信息 |
| 301 | Moved permanently | HTTP 响应的 Location header 应该提供资源的新 URL | |
| 302 | Moved temporarily | HTTP 响应的 Location header 应该提供资源的新 URL | |
| 304 | Not modified | 这个代码用来条件响应表示 Body 不需要再次被发送 | |
| 4xx(client error) | 401 | Bad request | 请求不能被理解,应该修改后重发 |
| 402 | Unauthorized | 表示没有权限 | |
| 403 | Forbidden | 通常表示你没有权限,或者你没有访问的票据 | |
| 404 | Not Found | 最广为人知的 HTTP 状态码,经常出现在错误页面上 | |
| 5xx(server error) | 500 | Internal server error | 由于服务器内部错误没有完成请求 |
| 501 | Not implemented | 服务器不认识这个请求(比如没有实现的 HTTP 方法) | |
| 502 | Bad gateway | 服务器表现的像是网关或者代理,从下游服务返回错误 | |
| 503 | Service unvailable | 服务器无法满足该请求,可能是因为服务器过载或者为了维护停机 |
精明的读者可能会注意到 HTTP/1.0 RFC 的早期草案中缺少一些状态码(203,303,402)。最终发布的 RFC 还删除了一些其他状态码。有些在 HTTP/1.1 中又被加上了,不过通常含义已经不同了。IANA(Internet Assigned Numbers Authority)维护所有 HTTP 版本中的所有状态码的完整列表,但是上表中 HTTP/1.0 中定义的状态码是最常用的那些。
显然有些响应含义是重叠的,比如一个不被服务端认识的请求可以是 400(bad request)或者 501(not implemented)。响应状态码被设计为表示宽泛的类型,每个应用程序都需要使用最合适的状态码。该规范还指出,响应状态码是可扩展的,因此可以根据需要添加新的状态码,而无需修改协议。这是对响应代码进行分类的一个原因。现有的 HTTP/1.0 客户端可能无法理解新的响应代码(比如 504),但是知道该请求是由于某种原因在服务端失败,并且可以按照处理其他 5xx 代码的方式处理该请求。
HTTP RESPONSE HEADERS
在第一行之后,是 HTTP/1 响应的 Header。请求的 Header 和响应的 Header 格式是相同的。两个 return 字符分隔 Header 和 Body,例子如下:
GET /
HTTP/1.0 302 Found
Location: http://www.google.ie/?gws_rd=cr&dcr=0&ei=BWe1WYrf123456qpIbwDg
Cache-Control: private
Content-Type: text/html; charset=UTF-8
Date: Sun, 10 Sep 2017 16:23:33 GMT
Server: gws
Content-Length: 268
X-XSS-Protection:1; mode=block
X-Frame-Options: SAMEORRGIN
<HTML><HEAD><meta http-equiv="content-type" content="text/html;charset=utf-8 "> <TITLE>302 Moved</TITLE></HEAD><BODY> <H1>302 Moved</H1> The document has moved <A HREF="http://www.google.ie/?gws_rd=cr&dcr=0&ei=BWe1WYrfIojUgAbqpI bwDg">here</A>.</BODY></HTML> Connection closed by foreign host.
随着 HTTP/1.0 的发布,HTTP 语法得到了极大的扩展,使其能够创建动态的,功能丰富的应用程序,而不仅仅通过简单的 HTTP/0.9 版本所允许的内容。HTTP 别变得更加复杂,从 HTTP/0.9 规范的大约 700 单次,增长到了 HTTP/1.0 的接近 20000 单词。但是即使该规范发布了,HTTP 工作组也只是将其看做记录当前使用情况的权宜之计,然后开始着手 HTTP/1.1。正如上面提到过的,HTTP/1.0 更多是为了记录当时已经被广泛使用的情况,而不是为客户端和服务端实现定义新的语法。除了新的响应代码外,RFC 的附录中还记录了其他方法(比如 PUT,DELETE,LINK 和 UNLINK)和其他的 HTTP Header,其中一些将在 HTTP/1.1 中标准化。HTTP 的成功使得在发明五年之后工作组就要努力跟上实现的步伐。
1.3.3 HTTP/1.1
如你所见,HTTP 是从版本 0.9 开始发布的,只提供了获取文本方法。这个版本从只处理文本发展到 1.0,并在 1.1 版本中进一步标准化和完善。正如版本建议一样,HTTP/1.1 是对 HTTP/1.0 的改进而不是颠覆的变革。从 0.9 版本到 1.0 是更大的改变,加入了 HTTP Headers。HTTP/1.1 进行了改进,使 HTTP 协议更好使用(比如持久连接,强制性服务器 Header,更好的 Cache 选项和分块编码 (chunk encoding))。或许更重要的是,它提供了一个正式的标准,可以作为万维网未来的基础。尽管 HTTP 的基本内容很容易理解,还是有许多复杂的地方可以用不同的方式来实现,并且缺乏正式的标准使得难以扩展。
第一个 HTTP/1.1 的规范在 1997 年 2 月发布(HTTP/1.0 发布九个月之后)。然后被 1999 年 6 月的版本代替然后再 2014 年有个第三个增强版本。每个版本都会废弃老的。HTTP 规范现在有 305 页,接近 100000 单词,表明了这个简单协议的发展程度以及阐明如何使用 HTTP 是多么重要。事实上,在撰写本文时,该规范将再次更新,预计在 2019 年初发布。根本上,HTTP/1.1 与 HTTP/1.0 没有太大的不同,但是 web 在过去 20 年的爆炸发展产生了丰富的附加功能,并要求文档提供精确的使用方法。
描述 HTTP/1.1 本身就可以完成一本书,所以这里尝试只讨论要点,以便为后面讨论 HTTP/2 提供背景和上下文。HTTP/1.1 的许多附加功能是通过 HTTP header 引入的,而 Header 是在 HTTP/1.0 中引入的,意味着两个版本的 HTTP 基本结构上没有改变,尽管 host header 成为了必选项以及添加了持久连接与 HTTP/1.0 有显著不同。
MANDATORY HOST HEADER
HTTP 请求行提供的 URL(例如 GET 方法)不是绝对 URL(http://www.example.com/section/page.html)而是相对 URL(/section/page.html)。当 HTTP 被发明时,假定 web 服务器只有一个网站,即使上面部署了很多 section 和 pages。因此 URL 的主机部分是显而易见的,因为用户必须在生成 HTTP 请求前连接 web 服务器。今天许多网站部署在同一个服务器上(被称为* virtual hosting*),所以告诉服务器时那个网站就变得与 URL 一样重要了。这个特性可以通过改变 URL 为绝对的解决,但是这个改变将会打破很多现有的网站运行方式。所以这个特性通过添加 Host header 来支持:
GET / HTTP/1.1
Host: www.google.com
这个 header 在 HTTP/1.0 是可选的,但是 HTTP/1.1 是必填的。下面的请求是错误的
GET / HTTP/1.1
根据 HTTP/1.1 规范,这个请求应该被服务器拒绝,返回 400 错误码,尽管大多数 Web 服务器宽容这种情况,并为此类请求返回默认主机。
让 Host Header 称为必填项是 HTTP/1.1 重要的一环,允许服务器使用虚拟主机,满足了 web 服务的巨大增长而无需为每个站点提供单独的服务器。此外,如果不进行此更改,IPv4 的 IP 地址将很快耗尽。另一方面,如果没有实施该限制,也许会迫使人们更早转向 IPv6,IPv6 推广过程已经持续了 20 多年。
强制 Host Header 而不是强制绝对 URL 引起了一些争议。HTTP/1.1 中引入的 HTTP 代理允许通过客户端通过代理连接 HTTP 服务器。代理的语法要求所有请求的 URL 是绝对 URL,但是实际的(也称为原始服务器)被强制使用 Host header。如上所述,这个保证了向后兼容,但是强制使用 Host 也使得 HTTP/1.1 客户端和服务端必须使用虚拟主机格式的请求才能完全兼容 HTTP/1.1 的实现。有人认为将来的某个 HTTP 版本,可以更好处理这种情况。HTTP/1.1 规范中指出,“为了允许将来某个 HTTP 版本转换所有请求为绝对 URL,服务器必须接受请求的绝对格式 URL,即使客户端只发送这种请求到代理”。不过,如你稍后所见,HTTP/2 不能彻底解决这个问题,而是将 Host Header 替换为:authority pseudoheader field(参阅第 4 章)。
PERSISTEN CONNECTIONS(AKA KEEP-ALIVES)
HTTP/1.1 引入的另一个重要变化时持久连接的引入,尽管 HTTP/1.0 中没有提到,但是实际上很多 HTTP/1.0 服务是支持的。最初,HTTP 是一个单次请求-响应协议。客户端打开链接,请求资源,获得响应,关闭连接。随着 web 越来越富媒体,关闭连接太浪费。展示一个单独的页面需要多个 HTTP 资源,所以关闭连接重连导致了不必要的延迟。这个问题可以使用新的 Connection Header 来解决,可以随着请求一起发送。通过这个 header 指定 keep-alive,客户端告诉服务器保持这个连接以发送其他请求。
GET /page.html HTTP/1.0
Connection: Keep-Alive
服务器如果支持持久连接,响应中也包含 Connection: Keep-Alive
HTTP/1.0 200 OK
Date: Sun, 25 Jun 2017 13:30:24 GMT
Connection: Keep-Alive
Content-Type: text/html
Content-Length: 12345
Server: Apache
<!doctype html> <html> <head> …etc.
这个响应告诉客户端,响应完成后,他可以在同一个连接上发送另一个请求,因此服务器不必关闭这个连接。当使用持久连接时知道何时响应完成变得更加复杂,连接关闭是一个很好的信号,表示服务端已经完成响应。替代方案是 Content-Length HTTP header 必须加入,表示响应消息的长度,当整个 body 都接收完成,客户端才可以发送另一个请求。
客户端或者服务器可以随时关闭 HTTP 连接,关闭可能是偶然的(比如由于网络错误)也可能是故意的(例如,如果一段时间未使用某个连接,并且服务器决定关闭它来重新连接到其他客户端)。因此即使具有持久连接,客户端和服务器也应该监视连接并可以处理意外的连接关闭。对于某些场景,这种请求可能变得更复杂。如果你要在电子商务网站上结账,可能不想在不检查服务器是否处理了原请求的情况下重新发送请求。
HTTP/1.1 不仅将持久连接添加到了标准中,还进一步将其定义为默认选项。即使响应中不存在 Connection header,也可以假定任何 HTTP/1.1 连接都在使用持久连接。如果服务器确实由于某种原因希望关闭持久连接,需要在响应中显示给出 Connection: close Header。
这里给出了可以 Telnet 测试一下三种情况
- HTTP/1.0 不带 Connection
- HTTP/1.1 带 Connection
- HTTP/1.1 不带 Connection
类似的主题,HTTP 添加了 pipeline,因此可以在同一持久连接上发送多个请求,并按顺序返回响应。如果 web 浏览器正在处理 HTML 文档,并且发现它需要一个 CSS 文件和一个 JavaScript 文件,可以将这些文件的请求一起发送,而不必先请求一个等收到响应之后在发送一个请求。这是一个例子:
GET /style.css HTTP/1.1
Host: www.example.com
GET /script.js HTTP/1.1
Host: www.example.com
HTTP/1.1 200 OK
Date: Sun, 25 Jun 2017 13:30:24 GMT
Content-Type: text/css; charset=UTF-8
Content-Length: 1234
Server: Apache
.style { …etc.
HTTP/1.1 200 OK
Date: Sun, 25 Jun 2017 13:30:25 GMT
Content-Type: application/x-javascript; charset=UTF-8
Content-Length: 5678
Server: Apache
Function( …etc.
由于一些原因(这里将会在第 2 章深入),pipeling 没有被实现过,并且在浏览器和服务端的支持都很差。因此,即使持久连接允许多个请求重复利用,并且有性能提升,HTTP/1.1 基本上还是一个请求-响应协议。当一个请求被处理同时,HTTP 连接是被 blocked 的不能发送其他请求。
OTHER NEW FEATURES
HTTP/1.1 还引入了很多其他特性,包括:
- 除了 HTTP/1.0 中的 GET,POST,HEAD 之外,新引入了 PUT,OPTIONS 和很少用的 CONNECT,TRACE,DELETE
- 更好的缓存方法。这些方法允许服务器告诉客户端在浏览器缓存中保存资源(比如 CSS 文件),在必要的时候可以重复利用。Cache-Control HTTP header 比 1.0 版本引入的 Expires 有更多的可选项
- HTTP cookies 可以将从无状态协议中增强为有状态
- 响应中字符集和语言的引入
- 支持代理
- 鉴权
- 新的状态码
- Trailing Headers(在第 4 章中,4.3.3 小节讨论)
HTTP 不断添加新的 HTTP header 以进一步扩展功能,许多处于性能或者安全性原因。HTTP/1.1 并没有表示最终定义,并鼓励添加新的 header,甚至专门介绍了如何在文档中定义新的 header。正如我之前提到的。这些 headers 中有些是为了安全原因,然后允许网站告诉 web 浏览器打开某些可选的安全保护,所以服务端没有任何实现(除了发送 header)。同时,header 中 X-的惯例是这不是标准规范中定义的 header(X-Conten-type,X-Frame-Options,X-XSS-Protection),但是这个惯例已经作废,新的实验性的 header 已经很难与 HTTP/1.1 标准区分开了,通常这些 header 有自己的 RFC(Content-Security-Policy,Strict-Transport-Security 等)。
1.4 Introduction to HTTPS
HTTP 是文本协议。HTTP 消息在网络中传输没有经过加密,因此看到该消息的任何一方都可以读取。顾名思义,计算机网络,不是端对端系统。Internet 无法控制消息的路由方式,作为 Internet 用户,你不知道从 ISP(Internet Service Provider) 到电信公司通过了那些组织的网络,还有多少其他地方可以看到你的消息。由于 HTTP 是纯文本格式,消息可以在中转途中被拦截,甚至被修改。
HTTPs 是一个通过 TLS(Transport Layer Security) 协议加密版本的 HTTP,尽管它的前身 SSL(Secure Sockets Layer) 的名字更广为人知 ,如下所述
HTTPS 往 HTTP 消息里加入了三个重要概念:
- Encryption -- 消息在传递过程中不能被第三方读取
- Integrity -- 消息不能再传递过程中修改,整个消息做了数字签名,并且在解密之前对该签名进行了验证
- Authentication -- 服务器是你想要通信的那个
SSL, TLS, HTTPS and HTTP
HTTPS 使用 SSL 或者 TLS 提供加密。SSL 由网景发明,SSLv1 没有公开发布,所以第一个版本是 SSLv2,在 1995 年发布。SSLv3 在 1996 年发布,提升了安全性
SSL 由网景拥有,尽管后来 IETF 将其作为历史文档发布了,但是不是正式的互联网标准。SSL 被标准化为 TLS。TLSv1.0 与 SSLv3 是相似的,但是不兼容。TLSv1.1 与 TLSv1.2 分别在 2006 年和 2008 年发布,更加安全。TLSv1.3 已经在 2018 年成为标准,更加安全和高效,尽管要花很多时间才能广泛使用
尽管有了更新更安全的标准化版本,许多人觉得 SSLv3 已经够好了,所以即使很多客户端已经支持了 TLSv1.0, 很长一段时间 SSLv3 还是事实标准。然而,在 2014 年,SSLv3 被发现了一个重大漏洞,浏览器将不再支持这个版本,这导致了向 TLSv1.0 的大迁移。在 TLSv1.0 也被发现重大漏洞之后,安全准则要求使用 TLSv1.1 或者更高版本
所有这些历史导致人们以不同的方式使用这些首字母缩写。长期以来,许多人仍然使用 SSL 作为加密名词,其他的则使用 SSL/TLS 或者 TLS。有些人试图使用 HTTPS 来避免这些名词冲突,即使这也不那么准确
本书中,我使用 HTTPS(而不是 SSL 或者 SSL/TLS)来描述加密,除非我要讨论 TLS 协议的特定部分。类似的,我将 HTTP 的核心语义称为 HTTP,无论用于加密的 HTTPS 连接还是未加密的 HTTP 连接。
HTTPS 通过公钥加密工作,在第一次与服务器通信时,公钥由服务器提供。你的浏览器使用公钥加密消息,只有提供公钥的服务器能解密。这个系统允许你在不知道共享秘钥的情况下与网站通信,这对于 Internet 这样的系统至关重要,因为每时每刻都有新的网站和用户。
数字证书是由浏览器信任的 CA 机构签发并进行了数字签名,这就是可以验证公钥是否适用于你要连接的服务器的原因。HTTPS 一个大问题是,只能表明你连上了公钥对应的网站,但是这不表明网站本身是安全的。伪装站点使用类似的域名(比如 exmplebank.com 与 examplebank.com)建立钓鱼网站。HTTPS 站点通常在浏览器显示为绿色的锁,许多用户将其视为安全,但是这仅意味着加密。
一些 CA 颁发证书时,提供扩展验证证书(称为 EV 证书),该证书与普通证书相同的方式对 HTTP 通信进行加密,不过大多数浏览器会显示公司名称。比如下图
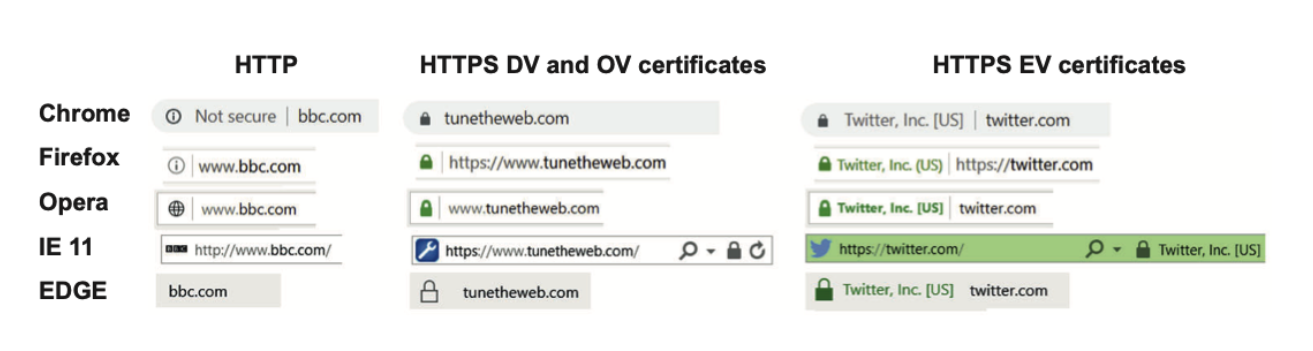
许多人对 EV 证书的好处提出质疑,因为大多数用户并没有注意到公司名称,然后将 EV 证书与 DV 证书的站点区分出来。中间组织 OV 会对证书做一些检查,但是不会给浏览器额外的通知,从而在技术层面显的毫无意义(尽管在购买证书时,CA 会对额外支持作出承诺)。
在撰写本文时,Google Chrome 小组正在研究和试验这些安全性指标,尝试移除一些没有必要的信息,包括 scheme(http 和 https),www 前缀,甚至可能挂锁本身(而是假设 HTTPS 是正常的,将 HTTP 明显标记为不安全)。同时他们也在考虑是否删除 EV。
HTTPS 围绕 HTTP 构建,并且几乎与 HTTP 协议本身无缝连接。默认情况下,托管在其他端口(443 端口而不是 HTTP 标准的 80 端口),有不同的 scheme (https:// 而不是 http://),但是除了加密和解密之外,对 HTTP 协议的语法没有任何改变
当客户端连接 HTTPS 服务器时,经过一个协商阶段(TLS 握手)。在这个过程总,服务器提供公钥,客户端与服务端关于加解密算法达成一致,然后协商一个未来通信使用的 encryption key(公钥加密很慢,所以公钥加密秘钥只用来协商共享秘钥,共享秘钥性能更好)。将在第 4 章详细讨论 TLS 握手过程(4.2.1)
在 HTTPS 会话初始化完成后,将交换标准 HTTP 消息,客户端和服务端将在发送消息前先对这些消息进行加密,然后再传输,然后解密,对于普通的 Web 开发人员和服务管理员来说,配置 HTTPS 和 HTTP 没有任何区别。除非你要查看网络收发的原始消息,否则一切都是透明的。HTTPS 将标准 HTTP 请求和响应封装起来而不是替换成另一个协议。
HTTPS 是一个巨大的话题,远远超出了本书的范围。由于 HTTP/2 确实在这方面有一些变更,在未来的章节会在此简单提到。但是现在,只要知道 HTTPS 的存在,并且在不影响 HTTP 标准协议的底层运行就行。除非你要看加密消息本身,否则你感受不到 HTTPS 和 HTTP 的不同。
对于使用 HTTPS 的服务器,你需要一个能理解 HTTPS 并加解密的客户端,所以你不能再用 Telnet 发送 HTTP 请求。 OpenSSL 提供了一个 s_client 命令让你可以向 HTTPS 发送 HTTP 命令,使用方式类似 Telnet:
openssl s_client -crlf -connect www.google.com:443 -quiet
GET / HTTP/1.1
Host: www.google.com
HTTP/1.1 200 OK
...etc
我们马上结束使用难用的命令行工具来试验 HTTP 请求的时代。下一节,我将要简要介绍浏览器工具,提供了更易用的方式。
1.5 Tools for viewing, sending, and receiving HTTP messages
略
Part2
在本书的第一部分,我介绍了 HTTP/2 的需要和动机,介绍了 HTTP/2 本身,描述了如何在你的站点部署 HTTP/2。对很多人来说,这些信息就足够了,即使不做任何改变升级到 HTTP/2 也能获得回报。HTTP/2 的设计易于迁移到大多数站点,并为它们带来了直接好处,而无需任何更改。
为了真正受益于 HTTP/2 所提供的所有功能,对协议及其工作原理有更深入的理解是很有用的。本书的这部分描述的协议核心的方方面面。第 4 和第 5 章覆盖了网站拥有者和开发利用 HTTP/2 协议的技术细节。第 6 章从协议本身触发,讨论了对 Web 性能的意义以及开发人员针对 HTTP/2 如何优化。
Part3
本书的第一部分介绍了 HTTP/2。第二部分了解了 HTTP/2 的细节以及如何使用。第 4 章介绍了 HTTP/2 的基本概念以及如何工作;第 5 章描述了 HTTP/2 的 PUSH,对于 HTTP 来说一个新的概念;第 6 章研究了 HTTP/2 应该或者不应该改变开发的实践。
本部分,继续更深入的探究,介绍一些鲜为人知的高级主题。第 7 章完成了规范中之前未涉及的部分,第 8 章单独介绍了 HPACK HTTP 头部压缩规范。这两章将帮助你从基础使用者转变为 HTTP/2 协议的专家。你将能解决任何 HTTP/2 的问题,甚至可以为不断发展的协议作出贡献。
Part4
到了这里,你应该对于 HTTP/2 有了深入的理解并完全了解了规范。在这最后的部分,我们来讨论一下 HTTP 的未来。HTTP/2 被越来越多的网站所使用,但是帮助定义 Internet 协议的人并没有为此感到骄傲。在某些方面,HTTP/2 是个老新闻,人们已经开始关注下一代改进的协议。
第 9 章介绍 QUIC。QUIC 是一种新协议,旨在继续 HTTP/2 的工作,并解决 TCP 层的问题。即将进行标准化(本书出版时可能已经标准化了),但是我猜测广泛使用可能需要更长的时间。QUIC 使用了 HTTP/2 的许多概念,因此读者应该可以很容易开始学习该协议,并可能很快用起来。
返回协议层,第 10 章,我继续讨论 HTTP 可能的演化。HTTP 已经很健壮并可扩展,HTTP/2 延续了这良好的传统,同时有很多选择可以使协议更进一步。
TCP,QUIC and HTTP/3
HTTP/2 的目的主要是通过允许单个多路复用连接来改善 HTTP 协议固有的效率低下问题。在 HTTP/1.1,该连接没有得到充分利用,因为一次只能用于一种资源。如果在响应请求时存在时延(比如因为服务器正忙于生成该资源),连接被 blocked 并且没有被使用。HTTP/2 允许多个资源使用同一个连接,因此在这种情况下其他资源可以使用该连接。
除了避免浪费连接之外,HTTP/2 还提高了性能,因为 HTTP 连接本书效率较低。建立 HTTP 连接需要一定的成本;否则多路复用不会得到真正的好处。成本不是由 HTTP 本身引起的,而是由用于建立此连接的两种基础技术决定的:HTTPS 中使用 TCP 和 TLS。
在本章中,我们讨论这些低效的问题,并表明尽管 HTTP/2 可以更好地处理这些低效的问题,但是某些情况下,由于这些问题,HTTP/2 可能比 HTTP/1.1 更慢。然后我们讨论 QUIC,看看如何针对这些问题进行改进。
9.1 TCP inefficiencies and HTTP
HTTP 依赖网络连接保证数据的可靠传递和有序性。直到最近,这种可靠连接使用 TCP 来保证。TCP 连接两个端(典型的是浏览器和 Web 服务器)然后确保消息传递的可靠性,如果消息丢失就重传,并且保证消息在传递给应用层(HTTP)时保持有序性。HTTP 不需要实现这些复杂的内容,而是假定已经满足这些条件。协议建立在这些假设之上。
TCP 通过给每个 TCP 包分配一个序列号,然后再接收端重排数据包(如果没有按序到达)或者要求重传丢失序列号的包(如果包丢失)。TCP 在 CWND 的基础上工作(这也构成了 HTTP/2 的流控制工作方式;参阅第 7 章),由此确定可发送的最大数据量(CWND 大小),已发送的消息减少了窗口大小,已确认的消息增大了窗口的大小。窗口开始时很小,但是随着时间推移而增长,因为网络容量表示可以承载更多的数据。如果客户端无法跟上进度,窗口也会缩小。这个过程运行得很好,TCP/IP 也因此成为 Internet 的基石。但是 TCP 的工作基本模式还是导致了五个主要问题,至少在 HTTP 方面是问题:
- 启动延迟。发送方和接收方必须在连接开始时就序列号达成协议。
- TCP 慢启动算法限制了 TCP 的性能,因为这会保守发送数据以尽可能避免重传
- 连接的使用不足会导致 TCP 的窗口回退。如果连接没有充分使用,TCP 降低 CWND 的大小,因为无法确定网络是不是有变更
- 丢包会使 TCP 性能下降。TCP 假设所有丢包是由于网络拥塞,但是不总是这样
- 数据包可能会排队,接收到乱序数据包会推迟传递到应用层来确保有序
这些问题在 HTTP/2 没有得到改善,其中有些问题是为什么使用单条 TCP 连接性能更好的原因。最后的两个问题,还会在有损条件下导致 HTTP/2 比 HTTP/1.1 性能更弱。
HTTP/2 标准在 HTTP/1.0 1.1 20年之后才被提出。这段时间里,互联网已经成为了大家生活的一部分,HTTP/1.1 广为传播。然而,长期以来,协议的停滞不前,而且由于 HTTP/1.1 的文档细节越来越多很难发展,并且增加 header 功能也越来越难。
现在 HTTP/2 出现了,并且迅速代替老协议,那么 HTTP 最终走向何方?HTTP/2 如何影响世界?HTTP 的问题已经解决了吗?下一代协议还会是20年之后吗,互联网的发展会不会缩短这个进程?本章尝试回答这些问题,并且做出 HTTP 演化的一些合理推测。